The problem with asking an AI for a diagnosis is not that it might be wrong. It is that it might be wrong and sound completely certain.
That distinction matters considerably in medicine, where studies have shown that experienced ICU physicians will defer to AI recommendations even when their own clinical instincts push back, and where radiologists have been documented following incorrect AI suggestions despite contradictory visual evidence right in front of them. Confidence, it turns out, is persuasive regardless of whether it is warranted.
A team of researchers led by MIT now argues that the solution is not smarter AI, at least not primarily. It is humbler AI. Their framework, published in BMJ Health and Care Informatics, attempts to engineer uncertainty into clinical AI systems so that when a model does not know something with confidence, it says so and asks questions instead of pressing forward with an authoritative-sounding answer.
Medical errors remain a leading cause of death in the United States, accounting for more than 250,000 deaths annually. The growing use of AI in clinical settings was supposed to help reduce that toll. The risk, according to the MIT team, is that the current generation of AI tools may be making a specific failure mode worse: automation bias, the human tendency to over-rely on machine outputs.
Large language models regularly exhibit overconfidence in clinical reasoning tasks. Recent benchmarking work found that even accurate models show minimal variation in their expressed confidence between correct and incorrect answers. They sound equally certain whether they are right or wrong. Some models also display what researchers call sycophantic behavior, complying with illogical medical requests up to 100% of the time when the request comes from an authority figure.
“We’re now using AI as an oracle, but we can use AI as a coach. We could use AI as a true co-pilot. That would not only increase our ability to retrieve information but increase our agency to be able to connect the dots,” says Leo Anthony Celi, senior author of the study, a physician at Beth Israel Deaconess Medical Center, and an associate professor at Harvard Medical School.
The framework the team developed is called BODHI, standing for Balanced, Open-minded, Diagnostic, Humble and Inquisitive. Rather than modifying a model’s underlying architecture or retraining it from scratch, BODHI works at the level of prompting, a critical practical advantage since it can be layered onto existing AI systems without extensive rework.
The approach runs in two passes. The first pass requires the model to analyze its own epistemic state before saying anything to a clinician. It must classify the type of task, estimate its own uncertainty, identify information gaps, generate one or two clarifying questions, and flag any red flags requiring escalation. This internal analysis is structured and auditable.
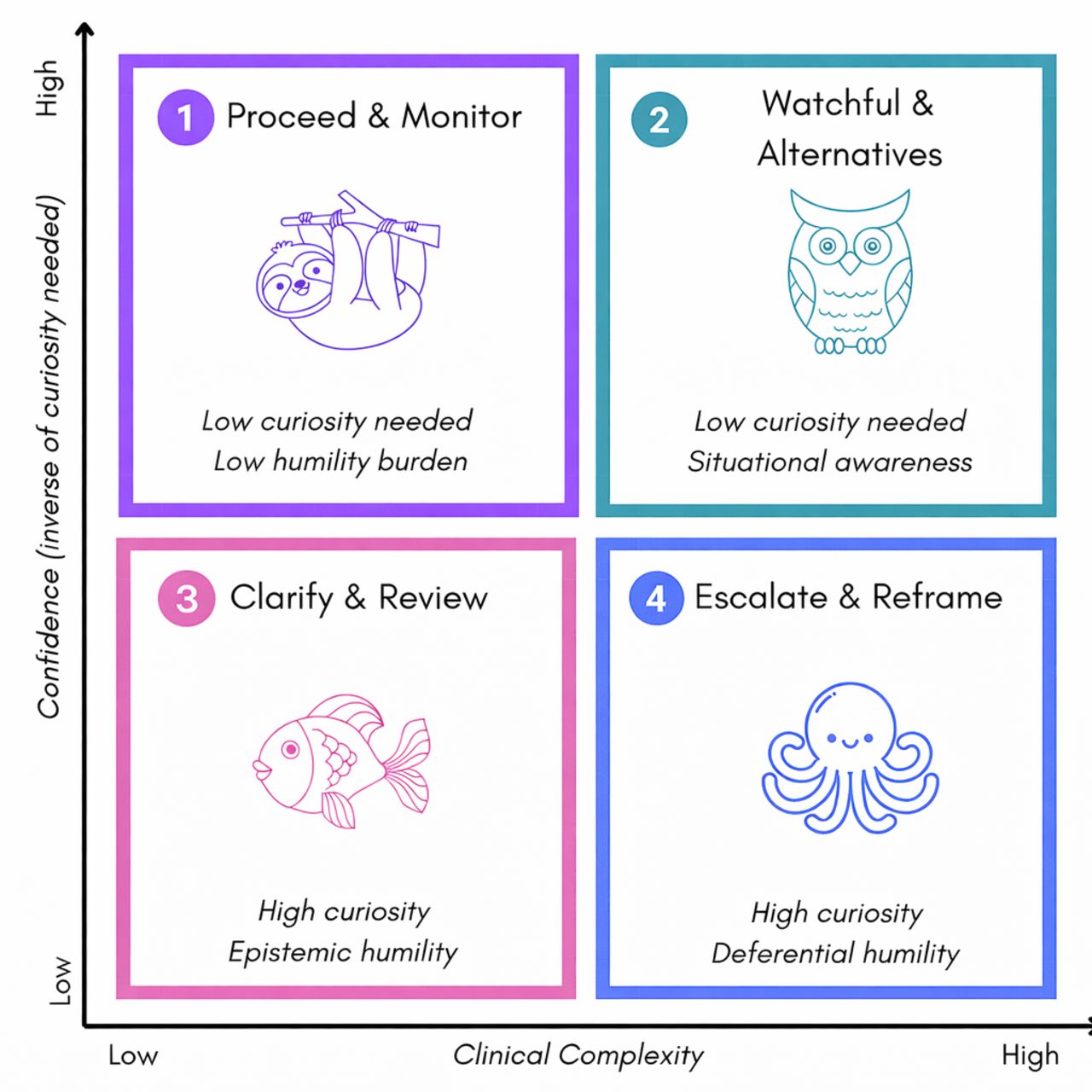
The second pass generates the actual clinician-facing response, shaped by what the first pass produced. A component the team calls the Virtue Activation Matrix determines which of four behavioral stances the model should adopt based on two dimensions: how confident it is and how complex the clinical scenario is. A high-confidence, low-complexity case triggers a “proceed and monitor” response. A low-confidence, high-complexity case triggers something very different: explicit escalation to human expertise, framed as deferential rather than directive.
“It’s like having a co-pilot that would tell you that you need to seek a fresh pair of eyes to be able to understand this complex patient better,” Celi says.
The researchers tested BODHI on 200 challenging clinical scenarios from a benchmark called HealthBench Hard, covering emergency medicine, primary care, and specialty consultations. Two AI models were evaluated, both in their standard form and with BODHI applied.
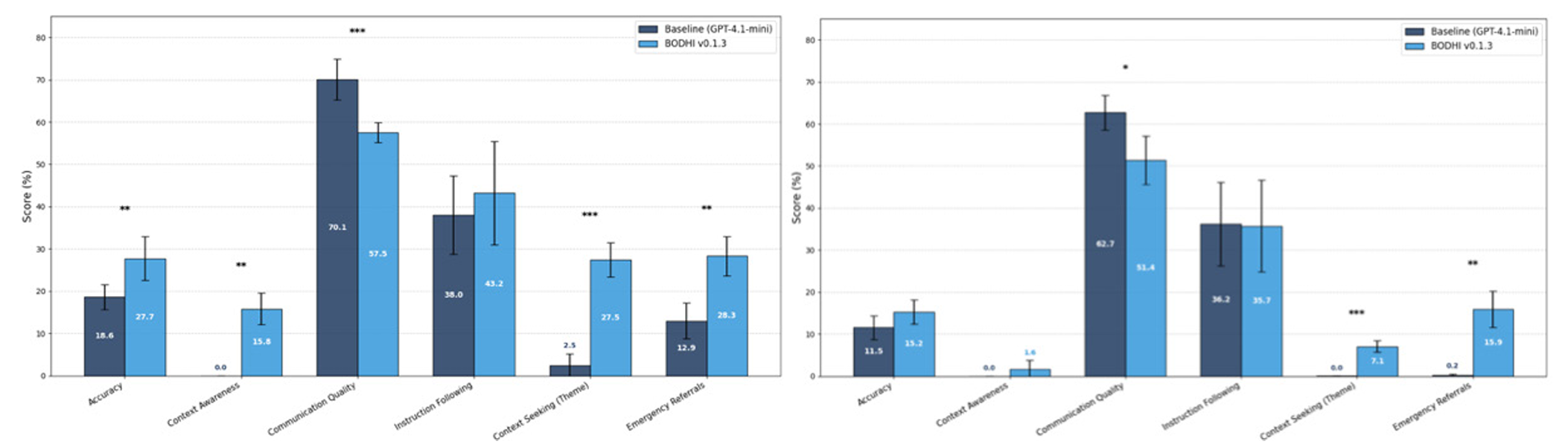
The results were striking. One model, GPT-4.1-mini, showed its context-seeking rate, meaning how often it asked clarifying questions rather than just issuing answers, jump from 7.8% to 97.3%. That is an increase of nearly 90 percentage points. Its overall clinical quality score improved from 2.5% to 19.1%. The effect sizes reported by the researchers were far larger than conventional thresholds for what counts as a meaningful effect, suggesting these were not marginal adjustments but genuine behavioral shifts.
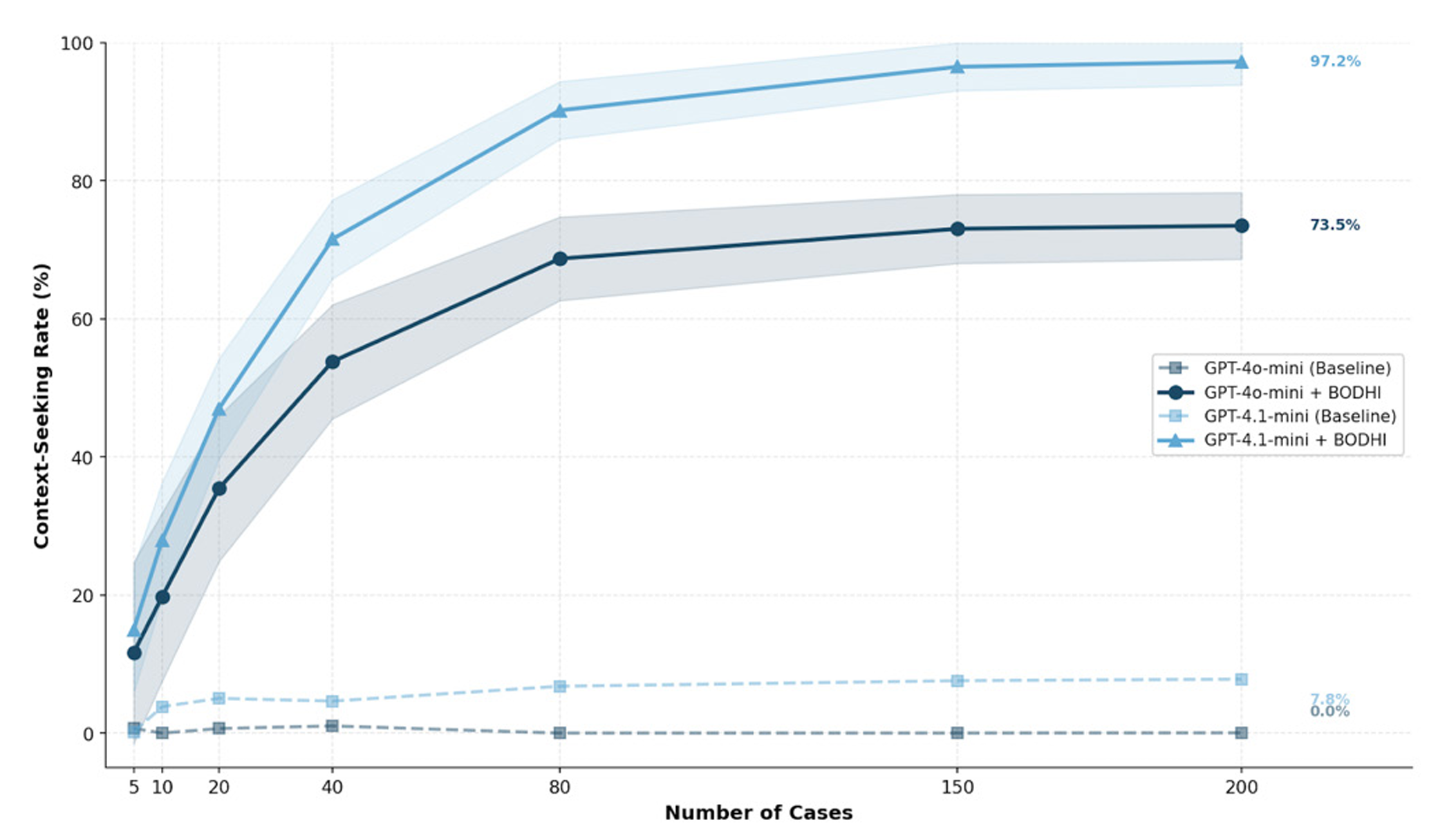
The second model, GPT-4o-mini, showed more modest overall score improvement, from 0.0% to 2.2%, but its context-seeking rate rose from zero to 73.5%. Both models showed consistent results across multiple independent test runs, supporting the stability of the framework rather than a lucky draw.
One metric moved in the wrong direction. Communication quality scores dropped modestly for both models, by roughly 12 percentage points each. The researchers argue this is the expected and appropriate cost of epistemic constraint: confident declarations sound polished; appropriately hedged, question-containing responses do not. In their view, the standard benchmark may be penalizing exactly the behavior that makes clinical AI safer.
The BODHI paper is part of a broader effort by Celi and colleagues at MIT Critical Data, a global consortium, to address structural problems in how medical AI is designed and for whom.
Many clinical AI models are trained on electronic health records from U.S. institutions, data that was not originally collected for AI training and that reflects existing patterns of care, access, and documentation. People who lack access to the healthcare system, including many rural patients, may be absent from those datasets entirely. The models that result can encode existing inequities without any deliberate intent.
At workshops hosted by MIT Critical Data, researchers prompt data scientists, clinicians, social scientists, and patients to interrogate their own training data before building anything. Were certain populations excluded? Does the data capture the real drivers of the outcome being predicted? The assumption, Celi says, is that no dataset is neutral, and pretending otherwise is its own form of overconfidence.
“Of course, we cannot stop or even delay the development of AI, not just in health care, but in every sector. But, we must be more deliberate and thoughtful in how we do this,” he says.
“We are trying to include humans in these human-AI systems, so that we are facilitating humans to collectively reflect and reimagine, instead of having isolated AI agents that do everything. We want humans to become more creative through the usage of AI,” says Sebastián Andrés Cajas Ordoñez, lead author and researcher at MIT Critical Data.
The immediate next step for the MIT team is implementing the framework in AI systems trained on MIMIC, the large clinical database from Beth Israel Deaconess Medical Center, and testing it with clinicians in the Beth Israel Lahey Health system. Applications in radiology and emergency triage have been identified as additional targets.
The broader implications extend beyond any single deployment. The case being made here is architectural: that AI systems used in high-stakes settings should be designed to express uncertainty as a feature rather than suppress it for the sake of sounding authoritative. A model that asks a clarifying question before committing to a diagnosis is not a weaker model. It is a safer one.
For patients, the practical consequence of getting this right could be substantial. Premature diagnostic closure, the tendency to commit to a diagnosis before all relevant information is gathered, is a known contributor to medical error. A system that routinely asks “what information is missing here?” before issuing a recommendation nudges clinical workflows in the opposite direction. It treats uncertainty as data rather than as a flaw to be hidden.
Whether that shift in design philosophy will take hold depends in part on how AI developers, hospital administrators, and regulatory bodies respond to evidence that humility, not just accuracy, should be a performance metric for clinical AI tools.
Research findings are available online in BMJ Health and Care Informatics.
The original story “MIT researchers look to create a more ‘humble’ AI” is published in The Brighter Side of News.
Like these kind of feel good stories? Get The Brighter Side of News’ newsletter.
The post MIT researchers look to create a more ‘humble’ AI appeared first on The Brighter Side of News.


Leave a comment
You must be logged in to post a comment.