The genetic code, a universal blueprint for life, governs how DNA and RNA sequences translate into proteins. While its complexity has inspired generations of scientists, its origins remain a topic of debate. New research from the University of Arizona challenges long-standing assumptions about how this remarkable code evolved.
A study led by Sawsan Wehbi, a doctoral student in genetics, suggests that traditional models of genetic code evolution need revision. Published in PNAS, the research argues that the widely accepted sequence in which amino acids—the building blocks of proteins—joined the code is flawed. This finding raises questions about the methods used to study the genetic code’s development.
“The genetic code is nearly optimal for numerous functions,” said Joanna Masel, senior author and professor of ecology and evolutionary biology at the University of Arizona. “It’s a mind-bogglingly complicated process, yet it must have evolved in stages. Our findings challenge the conventional narrative of its evolution.”
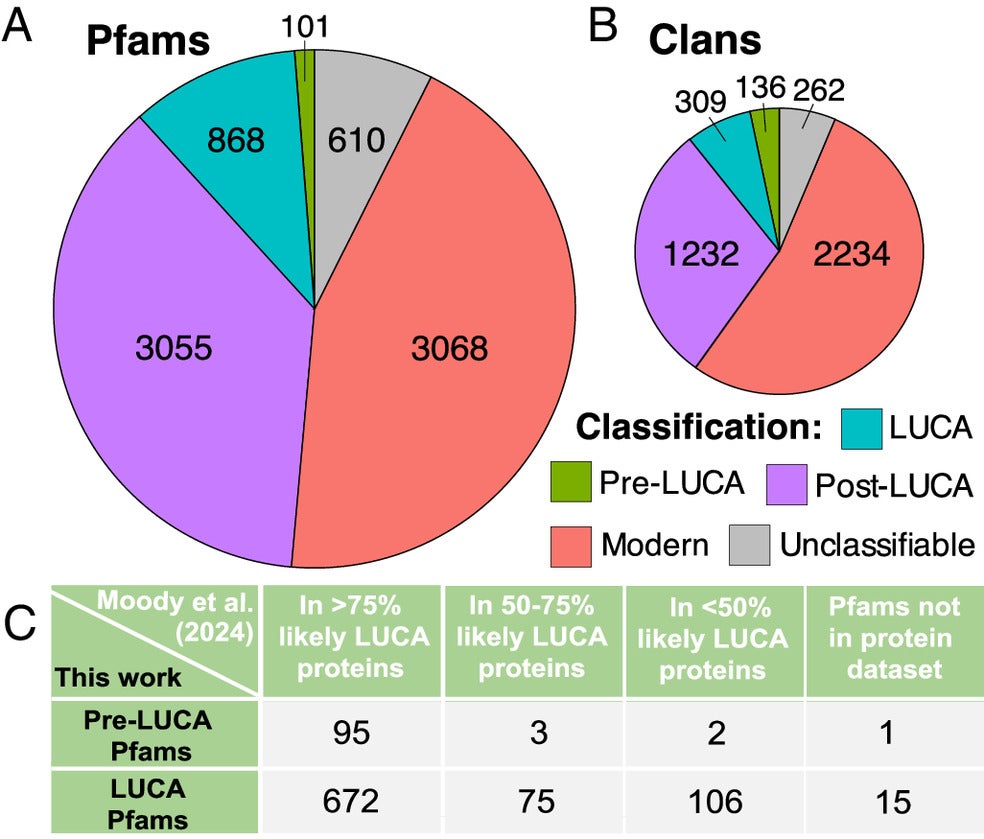
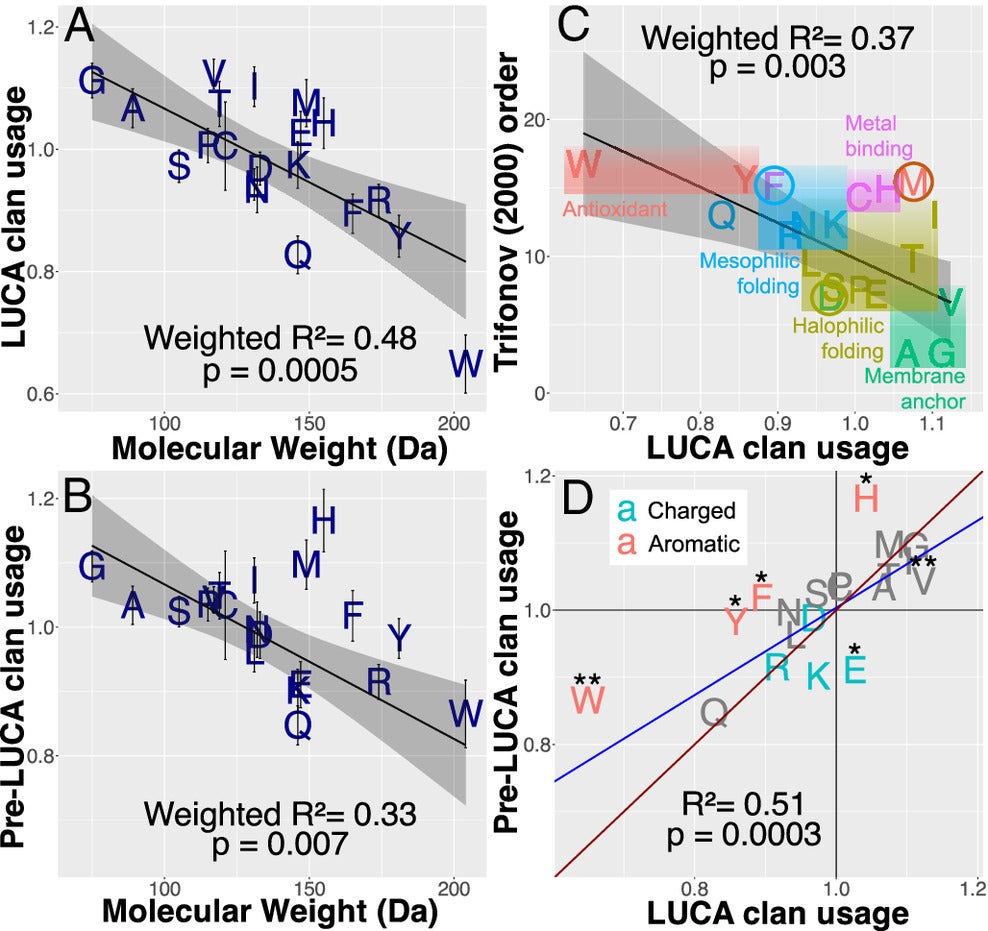
The study revealed three key insights: smaller amino acids were incorporated earlier than larger, complex ones; metal-binding amino acids appeared much earlier than previously thought; and today’s genetic code likely replaced earlier, now-extinct codes. These discoveries suggest a reevaluation of the scientific understanding of genetic code development.
Traditional theories, including those based on the 1952 Urey-Miller experiment, have long dominated the field. This groundbreaking experiment simulated early Earth’s conditions to demonstrate how life’s building blocks could arise from nonliving matter. However, it failed to account for sulfur-containing amino acids despite sulfur’s abundance on early Earth. As a result, sulfuric amino acids were erroneously labeled as late additions to the code.
“Sulfur was omitted from the experiment’s ingredients, so it’s not surprising that sulfur-containing amino acids didn’t appear,” explained Dante Lauretta, co-author and planetary science professor. “This oversight has profound implications for astrobiology, especially in the search for life on sulfur-rich worlds like Mars or Europa.”
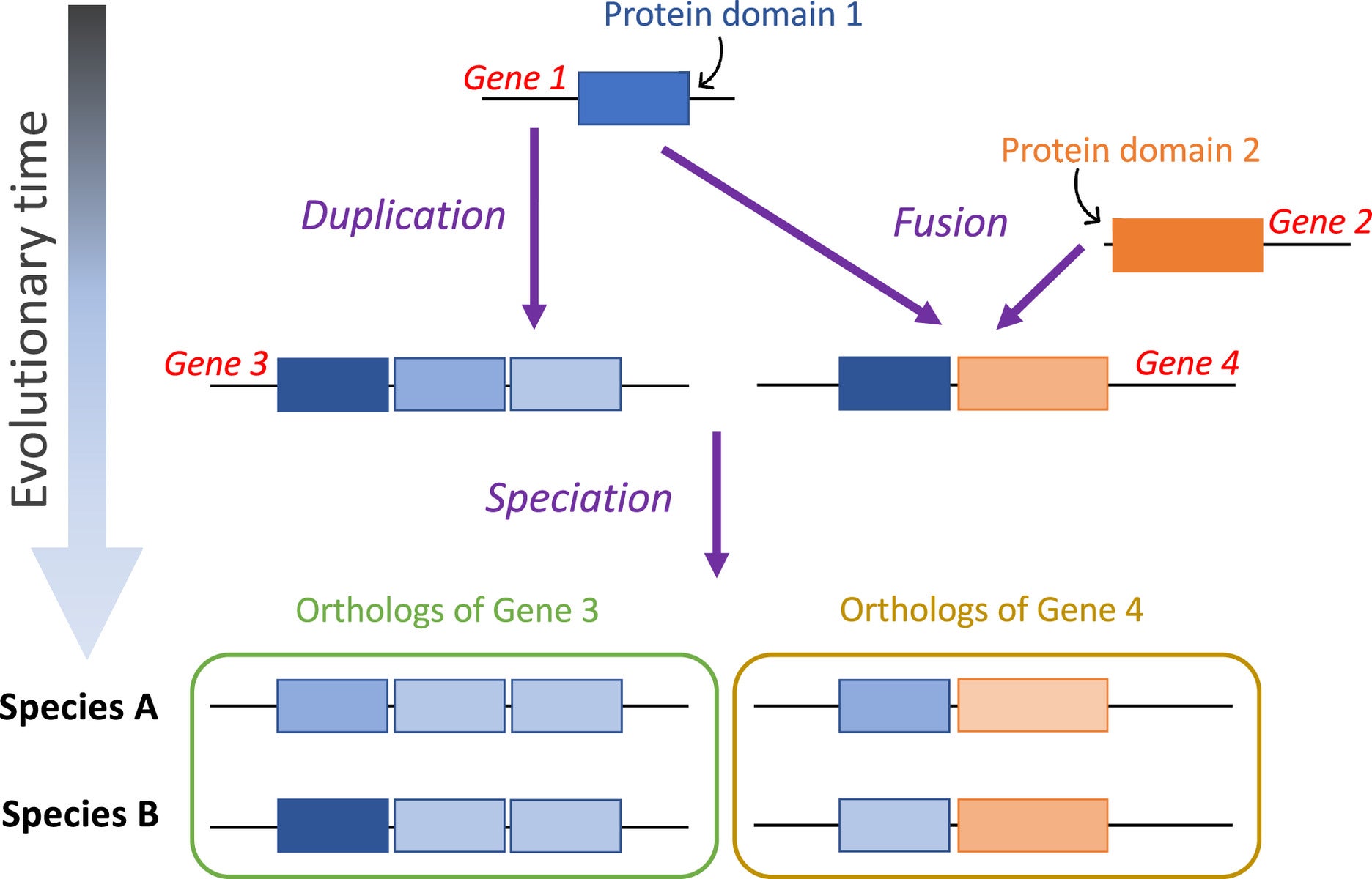
The new research uses evolutionary evidence rather than laboratory experiments to trace the genetic code’s origins. Instead of focusing on full-length protein sequences, the team examined protein domains—short, functional sections of proteins.
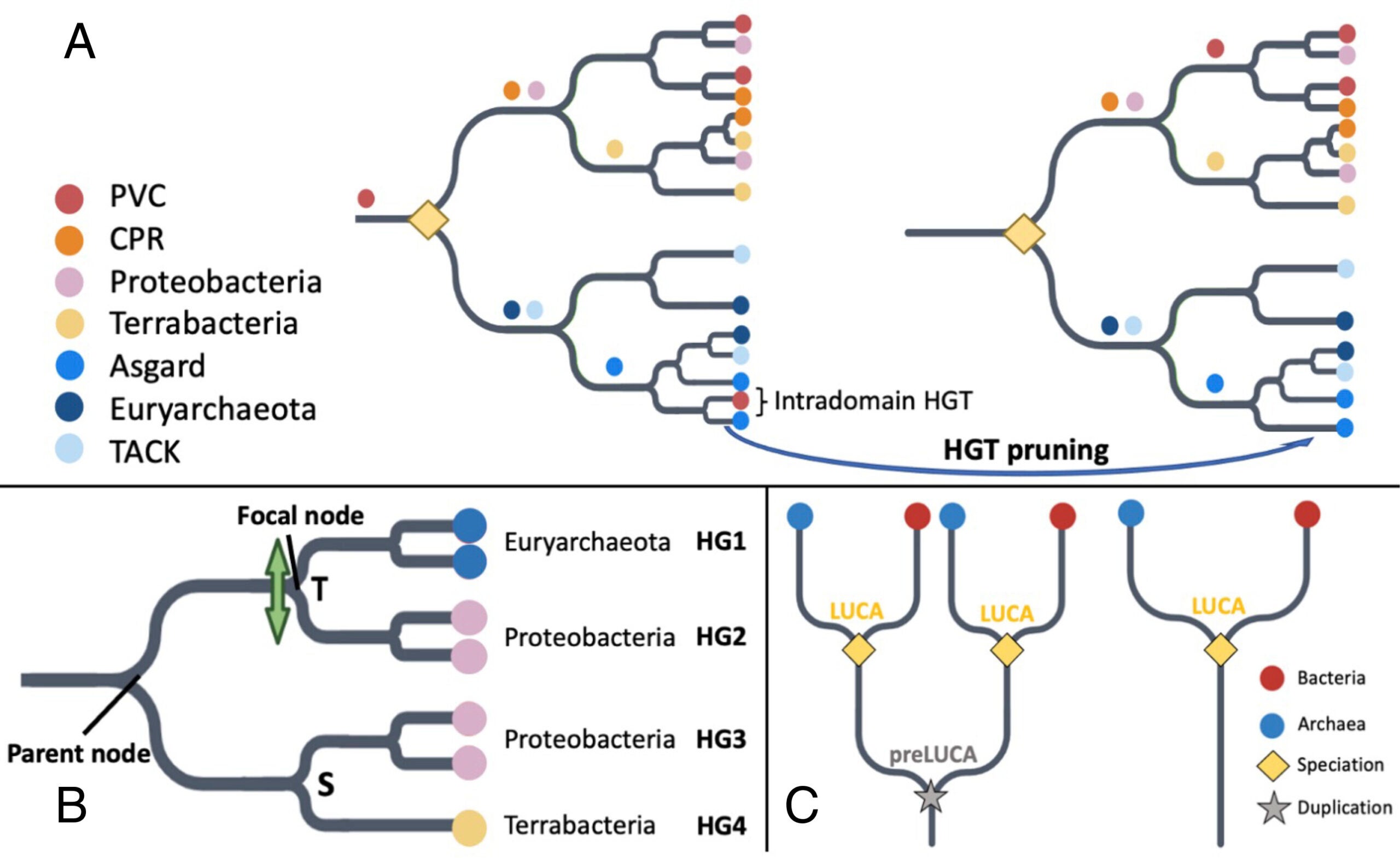
By analyzing sequences from the last universal common ancestor (LUCA), a population of organisms that lived about 4 billion years ago, the team identified over 400 families of sequences dating back to LUCA, with more than 100 predating it.
Related Stories
Wehbi likened protein domains to parts of a car. “If a protein is a car, a domain is like a wheel,” she said. “Wheels have been around much longer than cars.”
By comparing ancient and moderately ancient protein sequences, the researchers deduced when specific amino acids likely joined the genetic code. Amino acids more prevalent in ancient sequences were likely incorporated earlier, while those appearing less frequently were added later.
The findings overturn traditional views, particularly regarding amino acids like methionine, histidine, and aromatic ring structures such as tryptophan and tyrosine. Methionine and histidine, once thought to be late additions, are now considered early components due to their roles in metal-binding and purine-like structures.
The early presence of sulfur-rich methionine aligns with its role in essential biochemical pathways, such as the synthesis of S-adenosylmethionine, a critical molecule in cellular metabolism.
Histidine’s early inclusion is particularly significant given its importance in enzymatic activity. Although often classified as late due to its supposed unavailability in prebiotic environments, histidine’s structural resemblance to purines suggests it could have been biotically synthesized by early life forms. Its conservation in enzyme active sites underscores its evolutionary importance.
The study also highlights the role of aromatic amino acids, which were abundant in sequences predating LUCA. These findings hint at earlier genetic codes distinct from the modern one. “This gives clues about other genetic codes that existed before ours and have since disappeared,” Masel explained. “Early life seems to have favored aromatic structures.”
The research critiques previous methods of inferring amino acid recruitment, which often relied on abiotic availability. For instance, the Urey-Miller experiment’s exclusion of sulfur-containing amino acids misrepresented their evolutionary timeline.
Subsequent experiments have shown that sulfur-rich environments could produce amino acids like methionine and cysteine abiotically, challenging the consensus.
Furthermore, histidine’s early availability, despite its complex synthesis, suggests it may have been biotically produced by organisms already utilizing peptides. The study proposes that the evolutionary timeline should consider the biochemical needs of early life rather than just prebiotic abundance.
To infer the genetic code’s evolution, the team used statistical tools to analyze ancient protein sequences. Their approach differed from previous studies by focusing on protein domains rather than entire proteins.
Protein domains, which can function and evolve independently, offer a more precise understanding of the genetic code’s development. This method revealed that ancient proteins had distinct amino acid compositions compared to those emerging later.
The findings also challenge the “consensus” order of amino acid recruitment, which has limited predictive power. Smaller amino acids were added earlier, followed by those with specific biochemical properties, like metal-binding capabilities. The study emphasizes that evolutionary evidence, rather than abiotic synthesis experiments, should guide future research.
These insights have implications beyond Earth. The study’s findings on sulfur-rich amino acids could inform the search for extraterrestrial life.
“On planets and moons with sulfur-rich environments, such as Enceladus and Europa, we might find analogous biogeochemical cycles or microbial metabolisms,” Lauretta noted. “Understanding these processes could refine what we look for in biosignatures, improving our chances of detecting life beyond Earth.”
The genetic code’s evolution remains an intricate puzzle, but this study represents a significant step forward. By revising long-held assumptions and emphasizing evolutionary evidence, researchers are uncovering a more accurate narrative of how life’s blueprint came to be.
This work not only enhances our understanding of life on Earth but also guides the search for life in the universe.
Note: Materials provided above by The Brighter Side of News. Content may be edited for style and length.
Like these kind of feel good stories? Get The Brighter Side of News’ newsletter.
The post The universal genetic code, used by nearly all living organisms may be in need of a rewrite appeared first on The Brighter Side of News.

